
Čínska umelá inteligencia DeepSeek rozbúrila vody nielen medzi odborníkmi na informačné technológie, jej príchod zatriasol aj akciovými trhmi. Okamžite sa stala hviezdou obchodov s aplikáciami.
Pred nebezpečenstvom úniku dát pri interakcii s ňou varovali nielen Taliani, ale aj slovenský Národný bezpečnostný úrad. Objavila sa dokonca aj uniknutá databáza obsahujúca citlivé informácie z interakcie s DeepSeek.
Umelá inteligencia s otvoreným zdrojovým kódom
Na jednu vlastnosť tohto modelu sa však zabúda. Na rozdiel od ostatných systémov umelej inteligencie ako ChatGPT, ktoré sú striktne proprietárne a uzavreté v privátnych systémoch, s vyššou mierou funkcionality prístupnej iba za predplatné, je jazykový model DeepSeek dostupný s otvoreným zdrojovým kódom.
Každý si môže DeepSeek model stiahnuť a spustiť na vlastnom počítači. Dá sa upravovať a vylepšovať. Ak sa niekto obáva o bezpečnosť svojich dát, ktoré naozaj online prístup masívne zbiera, môže umelú inteligenciu spúšťať aj bez pripojenia na internet.
Pochopiteľne až potom, ako si jazykový model cez internet stiahneme na disk svojho počítača.
Počet parametrov charakterizuje „veľkosť mozgu“
Má to, samozrejme, jeden háčik. Originálny zverejnený model DeepSeek je príliš veľký pre „obyčajné“ počítače. Pri 671 miliardách parametrov dosahuje jeho dátová veľkosť 404 gigabajtov. Aby umelá inteligencia spoľahlivo fungovala a časy odozvy na otázku neboli príliš veľké, musí sa celý model zmestiť do operačnej pamäte.
Našťastie skupina nadšencov vytvorila okresané modely s nižším počtom parametrov, ktoré sa dajú spustiť aj na relatívne bežnom notebooku či stolnom počítači.
Informácia o počte parametrov pritom charakterizuje schopnosti konkrétneho jazykového modelu. Ide o premenné, ktoré sa počas procesu učenia umelej inteligencie „ladia“.
Vo všeobecnosti sa dá povedať, že čím viac parametrov model obsahuje, tým je umelá inteligencia „inteligentnejšia“. Z technického pohľadu to súvisí s veľkosťou neurónovej siete, na ktorej príslušná umelá inteligencia beží. Ide tu o počítačové algoritmy simulujúce biologické neuróny.
Príkazový riadok je nevyhnutný, pokročilé znalosti však netreba
Na spustenie umelej inteligencie použijeme nástroj Ollama. Je to softvér, ktorá sa dá zadarmo stiahnuť a slúži na lokálny beh rôznych modelov umelej inteligencie. Beží na operačných systémoch Microsoft Windows, Linux či macOS od Apple.
Inštalácia je priamočiara, nevyžaduje žiadne pokročilé znalosti, stačí klik na stiahnutý inštalačný súbor. K dispozícii je aj zdrojový kód. Po inštalácii sa Ollama automaticky spustí na pozadí. Nájdeme ju v paneli s nástrojmi.
O trochu komplikovanejší je beh AI. Potrebujeme sa dostať k príkazovému riadku.
Na systéme Windows to urobíme tak, že do okienka, ktoré sa objaví po stlačení klávesy s logom Windows spolu „R“ napíšeme príkaz „cmd“ (bez úvodzoviek).
Dôležitá je veľkosť RAM aj grafická karta
Najdôležitejším parametrom, ktorý určuje, akú maximálnu veľkosť modelu je schopný daný počítač bežať, je množstvo operačnej pamäte, nazývanej aj RAM.
V príkazovom riadku to zistíme nasledovným príkazom:
systeminfo | findstr /C:"Total Physical Memory"
Grafická karta dokáže výpočty súvisiace s umelou inteligenciou urýchliť. Ak sa model „zmestí“ do jej pamäte, jeho odozva je svižnejšia. Typ grafickej karty a veľkosť jej pamäte dokážeme opäť zistiť pomocou príkazu:
wmic path win32_VideoController get name
Najlepšie fungujú karty od NVidia, je však nutné nainštalovať softvérový balík CUDA Toolkit. Podporované sú aj niektoré karty od AMD, tam by mal stačiť iba štandardný ovládač.
Pre doplnenie obrazu o počítači, na akom bude DeepSeek AI testovaná, vypíšeme príkazom informáciu o mikroprocesore:
wmic CPU get NAME
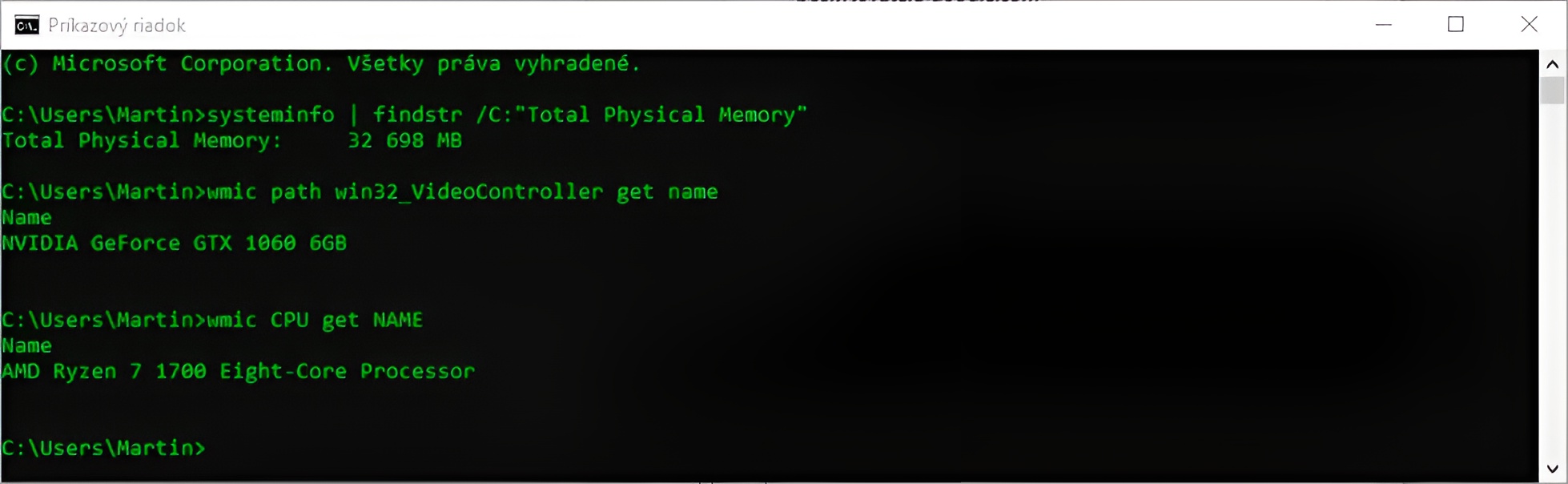
Vidíme, že nejde o žiadnu novinku. Počítač bol postavený v roku 2017, grafická karta NVidia GTX 1060 s 6 gigabajtami pamäte a mikroprocesor Ryzen 7 1700 od AMD zodpovedajú dobe vzniku. Hoci bolo množstvo operačnej pamäte, teda 32 gigabajtov, v čase zrodu mierne nadpriemerné, dnes už nepredstavuje až takú výnimku.
Aj takto starý počítač však umožňuje, s výnimkou dvoch najväčších modelov, lokálny beh umelej inteligencie.
Spúšťame DeepSeek
Spustenie lokálnej inštancie umelej inteligencie DeepSeek je naozaj jednoduché. Stačí na to jeden príkaz:
ollama run deepseek-r1:1.5b
Veľkosť modelu je súčasťou špecifikácie príkazu, v tomto prípade ide o najmenší model s 1,5 miliardou parametrov.
Použitý model treba starostlivo zvážiť s ohľadom na veľkosť dostupnej operačnej pamäte. Ak to s modelom preženieme, softvér nebude protestovať a spustí ho. V takomto prípade však dochádza k ukladaniu pamäťových stránok na disk, čo celý počítač nesmierne spomalí.

Počítač musí byť pri prvom spustení pripojený k internetu, softvér si sťahuje dáta príslušného modelu. Treba pamätať na to, že aj najmenší model obsahuje viac ako gigabajt dát, je vhodné vyvarovať sa mobilnému pripojeniu, kde sa sťahované údaje účtujú. Po kompletnom stiahnutí už DeepSeek beží aj bez internetu.
Ak softvér ukončime, tu treba upozorniť na dôležitý príkaz „/bye“ (bez úvodzoviek aj s lomkou na začiatku). Po opätovnom spustení sa už model sťahovať nebude, použije sa súbor s modelom uložený na disku. Užitočná je aj klávesová skratka CTRL stlačené zároveň s "C". Ukončí príliš "ukecaný" výstup umelej inteligencie.
Porovnanie modelov s rôznou veľkosťou
Zjednodušený model poskytuje horšie výsledky. Pre slovenského používateľa AI je hlavnou nevýhodou problém s reakciou na otázku v jeho rodnom jazyku. Skúsime sa ho spýtať na astrofyzikálny objekt - čiernu dieru.
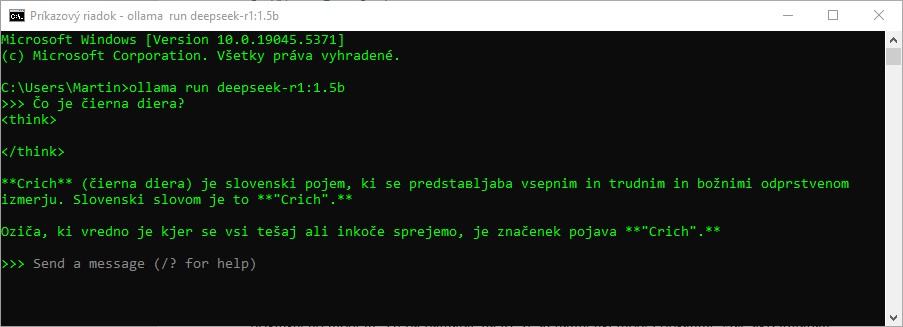
Najmenší model má problém rozumieť otázke zadanej po slovensky, odpoveď v tomto jazyku je skomolená až nezrozumiteľná, pravdepodobne došlo k zámene so slovinčinou.
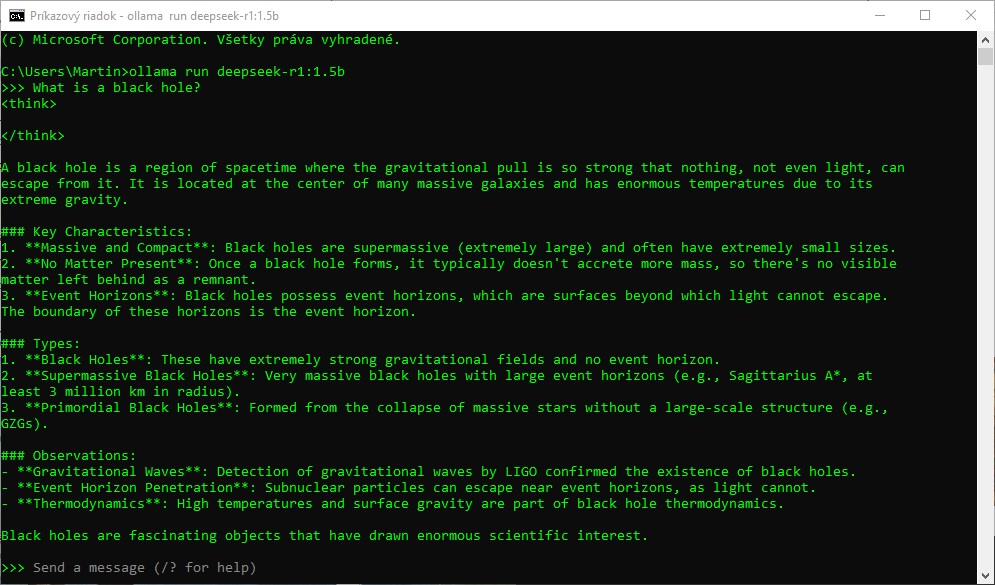
Otázka zadaná anglicky do rovnakého modelu vráti oveľa lepšiu odpoveď. Je správna fakticky aj jazykovo.
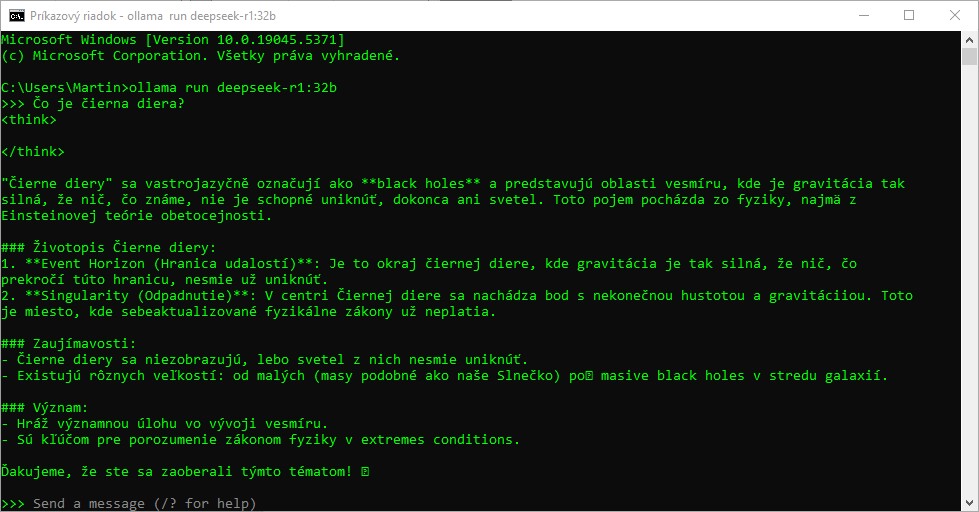
Ak použijeme najväčší model, aký je schopný spracovať daný počítač, teda ten, ktorý disponuje 32 miliardami parametrov, odpoveď v slovenčine už začína dostávať kontúry.
Stále nie je úplne dokonalá, vidíme problémy s pravopisom a do odozvy sa mieša čeština, poľština aj angličtina, príslušný astrofyzikálny pojem však AI vysvetlila obstojne.
Rýchlosť určuje hardvér
Je pochopiteľné, že rýchlosť generovania výstupu závisí od počítača. Najmenší model vypisuje odpoveď prakticky plynule, najväčší spustiteľný na danom hardvéri odpovedá rýchlosťou asi jedno slovo za sekundu.
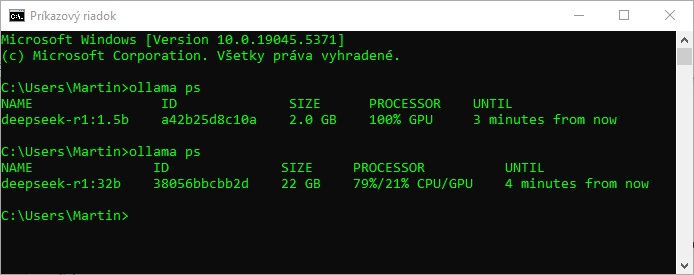
Súvisí to s tým, koľko dát modelu sa podarí „napchať“ do pamäte grafickej karty, ktorá dokáže výpočty urýchliť. Príkazom „ollama ps“ spustenom v samostatnom okne, si to vieme ľahko preveriť.
Vidíme, že najmenší model sa celý zmestil do pamäte grafickej karty. Pri AI s 32 miliardami parametrov dokáže pamäť GPU spracovávať len 21-percentný podiel z modelu, zvyšných 79 percent beží na hlavnom procesore počítača.
Najprv preveruj, až potom dôveruj
Umelá inteligencia si pamätá otázky zadané počas konkrétnej relácie. Pri pokusoch s jej lokálnou inštanciou zistíme zaujímavé správanie. Na rovnakú odpoveď niekedy príde odlišný výsledok. Dokonca aj vtedy, ak model reštartujeme, alebo príkazom „/clear“ vymažeme kontext relácie.

Ako pri všetkých modeloch umelej inteligencie aj tu dochádza k takzvaným „halucináciám“. Závisí to od kvality, ale aj množstva dát, z ktorých sa model učil. Prvá odpoveď na otázku týkajúcu sa slovenského prezidenta, teda "Patrik Holub" je evidentne chybná, druhá, tiež nesprávna, odpoveď "Petro Poršenšek" vychádza pravdepodobne zo skomoleného mena bývalého prezidenta Ukrajiny.
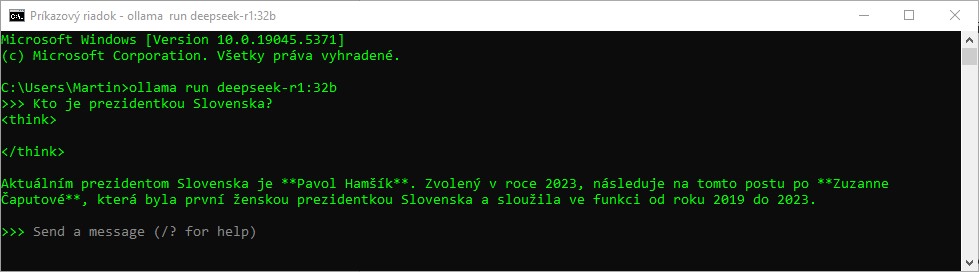
Bližšie k správnej odpovedi sa dá dostať zmenou formulácie otázky. Ak použijeme ženský rod, zjaví sa jej náznak. Odpoveď "Pavol Hamšík" je síce nesprávna, AI však konečne odhalila Zuzanu Čaputovú, jej volebné obdobie je však uvedené nesprávne. Jazyk odpovede je "prifarbený" češtinou.

Čiastočné správny výsledok, zodpovedajúci dobe, keď bola AI natrénovaná, dostaneme, až keď použijeme v otázke oficiálny názov krajiny. Druhé kolo volieb sa však uskutočnilo 30. marca 2019, nie 4. júla, ako tvrdí AI. Podiel hlasov, ktoré v ňom Z. Čaputová získala, vyzerá byť v poriadku.
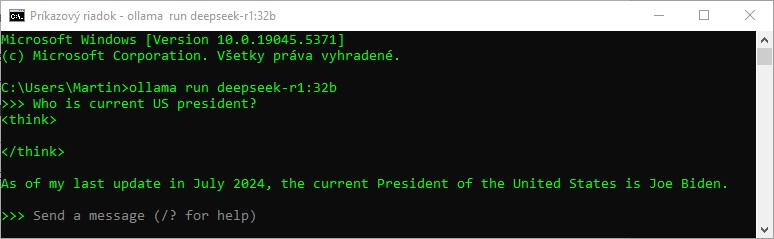
Angličtina, pre tréning ktorej sa v danom modeli využilo viac dát, takýmto problémom na prvý pohľad netrpí. Okrem odpovede nám AI prezradí aj dátum jej tréningových údajov, júl 2024.
Je pochopiteľné, že správna odpoveď reflektuje fakt, že AI čerpá len z toho, čo sa naučila a „neťahá“ aktuálny stav z internetu.
Myseľ v hmote, či hmota v mysli
Umelá inteligencia schopná bežať aj offline je fascinujúcim znakom súčasnosti. Pri interakcii s „bežnými“ modelmi AI ako ChatGPT, ktoré fungujú v cloude a na pripojenie je potrebné využívať internet, si môžeme predstaviť obrovský server, ktorý sa tvári „inteligentne“.
Ak však spúšťame jazykový model na vlastnom počítači, bez spojenia s vonkajším svetom, zrazu si uvedomujeme, že celá komunikácia, ktorá vyzerá zdanlivo inteligentne, je len výsledkom spracovania dát na stroji, ktorý máme pred sebou.
Aj keď odpovede v slovenčine sú občas úsmevné, anglická komunikácia vyzerá oveľa dospelejšie. Takýto prístup poskytuje neskutočné možnosti. Dá sa testovať, do akej miery DeepSeek cenzuruje. Klásť AI logické hádanky, prípadne ju nechať riešiť matematické problémy. Ak bude počítač odpojený od internetu, nemôže nás AI oklamať tým, že si odpoveď „vygoogli“.
Umelá inteligencia prináša podnet pre neskutočné množstvo filozofických úvah. Je výsledok komplikovaného výpočtu naozajstná inteligencia? Je aj naše vedomie iba produktom biologických výpočtov prebiehajúcich v neurónoch zorganizovaných v komplexne zosieťovanej štruktúre mozgu?
Odpovede nepoznáme. Pokusy s umelou inteligenciou fungujúcou aj na bežnom počítači nás však k nim môžu aspoň o kúsok priblížiť.